
最近在研究 Keras 與深度學習,順便記錄一下學習的過程 (完整 Keras 投影片)。現在網路上已經有很多的資源可以幫助我們進行 Machine Learning,像是 GPU 可以用 CoLab 提供的 P100 來訓練,足夠應付一般的實驗工作。如果要訓練比較龐大的影像資料,還是自己買 GPU 或租用雲端 MaaS 服務吧,不然免費的 CoLab 穩定性不太夠,而且只有一顆 GPU。因為學習心得有點多,內容可能會分幾篇文章進行介紹。廢話說完,那就先開始吧......
Keras 是什麽?
Keras 是近年火紅的 Machine Learning 函式庫,也是一個開源專案,透過 Python 實做的深度學習高階 API 函式庫。採用 MIT License,主要作者維護者是 Google 工程師 François Chollet。在 GitHub Keras Project 獲得超多的 Star 與 Fork。
Keras 擁有以下特性:
- 相同的程式碼可以在 CPU 或 GPU 上執行
- 提供 API 快速建構神經網路雛型
- 內建函式庫支援卷神經網路、循環神經網路以及任何組合
- 可建構任何形式的深度學習模型,包含對抗神經網路、神經圖靈機
- 內建 Play Dataset,可以進行一些演算法的實驗
架構如下:

為什麽現在「深度學習」高速發展?
類神經網路的概念很久以前就已經被提出,早期計算機運算能力有限,那時候只能解決簡單問題,比如訓練一個 XOR 互斥或閘 (XOR Problem) 這樣的問題。如今伴隨科技的進步,以往複雜的問題所需要的大量運算,逐漸被克服,以下幾點也是近年來 Machine Learning 發展迅速的主因:
- 硬體設備提昇:GPU, CUDA 平行運算 (Nvidia)
- 資料:伴隨網路發展產生大量的資料、標記內容
- 演算法:更好的啟動函數、更好的權重初始化方法、更好的最佳化方式
其中我認為半導體的技術發展是最大的推手,利用半導體發展 AI 運算專用的晶片,或者未來實現 In-memory Processing 這樣的晶片架構,都會大幅提昇 AI 解決問題與應用的能力。
機器學習的基本概念
如果你跟我一樣也是個程式 (Bug) 設計師,那麼我們平常的工作應該是:

沒錯,就是理解正妹 PM 提出的需求,經過專業的系統分析師 (應該也是你) 分析以後,接著由軟體架構師 (應該也是你) 進行系統設計,然後交給程式設計師 (還是你) 進行設計。這樣的開發過程就是現在程式設計的流程,所有的「答案」都是我們可以預測的 (我是說大部分比較正常的情況下),而我們實現「規則」的過程就是程式設計,但有時候規則很難被歸納與實現,說的出來但是很難收斂與系統化,比如從一張照片分辨是貓還是狗。
像這一類的問題對人類來說很簡單,對機器來說卻是很複雜。相較於傳統的程式設計,機器學習的過程就不太一樣:

首先我們要準備很多「答案」與「資料」作為訓練樣本,然後假設這個規則可能構成的方法,接著讓機器根據我們提供的答案與資料進行訓練,嘗試找出兩者之間的「規則」關係。這類的問題通常都是很難用傳統的「程式設計」來解決的問題,甚至有一些模糊地帶與不容易量化的問題答案,就可以透過機器學習 (深度學習) 來完成。
除了深度學習,還有淺層學習
除了深度學習用到的類神經網路,還有一個領域是機器學習常用的方法,統稱淺層學習。這個詞比較少見,其實就是一些傳統的統計方法,這些其實都是透過「資料與答案」尋找「規則」,當然也屬於機器學習的一部分。這些常用的方法如下:
機率建模 (Probabilistic modeling)
- 單純貝式分類器
- 邏輯斯回歸 (Logistic Regression)
Kernel Methods
- SVM - 將資料投影到高維空間,進而尋找最佳決策邊界。難以用在大量的資料集,像是影像處理領域。屬於淺層工作法,其中「特徵工程」就變得相當重要。
決策樹、隨機森林、梯度提昇機器
- 決策樹 (Decision tree)
- 隨機森林 (Random Forest):集合大量決策樹組合輸出值,在 2010 ~ 2014 廣授歡迎。
- 梯度提昇機 (Gradient Boosting Machines, GBM):適合處理非感知資料,透過迭代訓練逐步提昇模型的弱點,也稱為弱預測模型。
上述的方法大家應該多少有些聽聞,我就不一一介紹了 (我也不懂 R~~~)。
類神經網路 ANN
會被稱為類神經網路 (Artificial Neural Network,ANN),是因為組合的結構與人類腦中的神經元相似,目前在機器學習上使用的神經網路規模的架構,與人類腦中的神經元組成大不相同,無論是複雜度與數量都無法與人腦相比。現在可以透過 HPC 處理比較龐大的類神經網路,用來解決複雜的問題,一個簡單的神經網路如下:
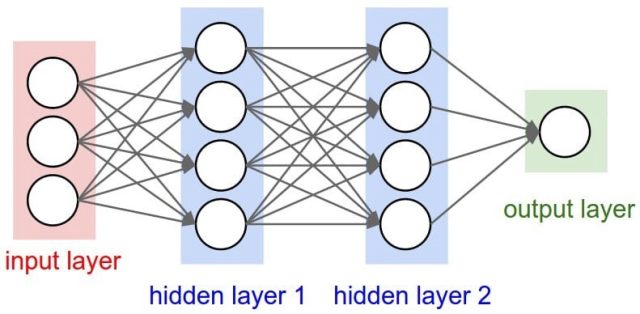
一個類神經網路由許多 Layer 組成,透過 Input 與 Output 給予資料來訓練 Layer 中的參數。類神經網路就像一個龐大的「多項式」,需要大量計算才能求得最佳解。如今類神經網路已經發展出非常多樣的網路模型,透過不同的神經元連接方式、資料處理方式、參數調整方式、收斂方式來建立 AI 模型,應付各種問題。
類神經網路的概念就像一個黑盒子,理論上可以學習任何規則 (是理論!?),在很早期 1975 年 Paul Werbos 發明的反向傳播算法 (Backpropagation) 就成功訓練了「互斥或」邏輯運算,一直到近幾年積體電路 GPU 突飛猛進,可以進行複雜與龐大的運算,也讓神經網路開啟進入到另一個階段。
為什麽現在「深度學習」高速發展?主要以下幾個原因:
硬體設備提昇:GPU, CUDA 平行運算 (N-Vidia)
資料爆炸:伴隨網路發展,產生大量的資料、標記內容
演算法:更好的啟動函數、更好的權重初始化方法、更好的最佳化方式
深度學習的基本概念
深度學習的基本架構,透過不同的「網路層」連接方式,可以產生不同的 AI Model,解決不同的問題。
那麼深度學習是如何運作的?以監督式學習為例,我們需要先準備很多「輸入資料 X」與「標準答案 Y」然後送進網路進行運算。藉由不斷調整參數來找到「解法」,一開始我們就會定義網路的組成方式,這個網路代表一個假設空間,藉由我們輸入的資料讓這個假設空間 (網路) 可以找到解法。但如果我們一開始設定的假設空間 (網路) 就已經沒有涵蓋最正確的解法,那麼無論怎麼運算都不會有好的結果,所以一開始網路的架構選擇與組成也是很重要的。整個訓練過程如下圖:
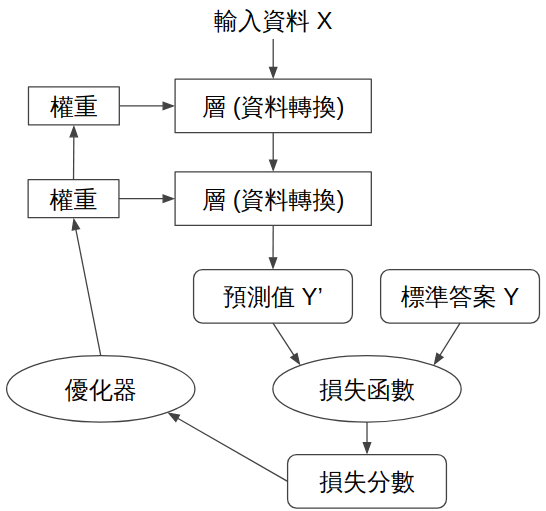
上圖當「輸入資料 X」經過網路的計算後,會獲得答案「預測值 Y'」但是一開始這個答案給我們的「標準答案 Y」會有一些差距,基本的訓練架構會透過「損失函數」計算出「損失分數」,藉由我們選擇的「優化器」逐漸優化調整網路權重值,好讓我們的「預測值 Y'」可以慢慢接近「標準答案 Y」。
經過數輪的計算後這個「超級函式」就會擬合 (Fit) 我們的輸入資料,當未來送入一樣概念的資料時,網路就能輸出這個概念所理解的答案。
這篇文章是我今年 K 書整理下來的心得,後續會慢慢介紹其他 Keras 的用法....... 下次見~