
Keras 教學 - 利用二元分類器訓練 IMDB 深度學習演算法
前一篇文章介紹了機器學習最基本的 Hello World = MNIST 模型訓練。今天換一個 IMDB Reviews 的 Play Data 例子玩看看,對於如何透過 Keras 訓練神經網路的基本概念,可以參考前一篇「Keras MNIST 手寫辨識 x 深度學習的 HelloWorld」文章介紹。
二元分類或稱兩類分類可能是在機器學習中應用最廣泛問題。只要處理的問題只有兩個結果,就可以適用。在這個例子中,我們將根據 IMDB 評論的文本內容將電影評論分為「正面」評論和「負面」評論。
關於 IMDB Dataset 資料集
IMDB Dataset 是來自 Internet 電影數據庫 50,000 條評論文字。他們分為 25,000 條訓練數據和 25,000 條測試數據,每組皆包含包括 50% 的負面評論和 50% 的正面評論。
我們可以直接透過 Keras Datasets 函式庫載入已經整理好的資料集。這些資料集已經經過處理,會將評論依據單詞順序,排列為整數序列,其中每個整數代表字典中的特定單詞。如下:
from keras.datasets import imdb (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
num_words=10000 表示我們只採用前 10000 個常出現的字詞,此外在 label 中 0 表示負評 1 表示正評。
max([max(sequence) for sequence in train_data])
也可以透過字典檔,將資料組合回評論文字。
word_index = imdb.get_word_index() reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]]) # show decoded_review
IMDB Reviews 資料前處理
我們無法將代表字典檔索引位置的整數資料直接送進網路進行訓練,因此需要對資料進行轉換。由於我們只採用前 10000 常用字詞作為資料集,因此輸入資料可以轉換為 10000 維度的 one-hot-encode,例如 [3, 18] 表示一個全部都是 0 的陣列,只有 index 3, 18 是 1。我們會將這樣的資料格式作為張量進行訓練,轉換如下:
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
# Create an all-zero matrix of shape (len(sequences), dimension)
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. # set specific indices of results[i] to 1s
return results
# Our vectorized training data
x_train = vectorize_sequences(train_data)
# Our vectorized test data
x_test = vectorize_sequences(test_data)
將結果標記進行正規化
# Our vectorized labels
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
建立 CNN 網路架構
這裡我們預計使用三層網路,全連接層僅使用兩層 16 個神經元的網路,啟動函數設定為 relu,連接最後使用一個神經元輸出(表示正評或負評),並使用 sigmoid 作為最後輸出的啟動函數。由下而上網路架構如下:
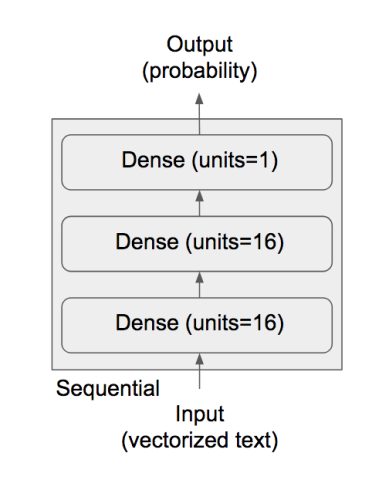
預計採用的 CNN 詳細定義如下:
- 訓練 Dataset:25,000
- 測試 Dataset:25,000
- 優化器:RMSprop
- 損失函數:二元分類
- Batch Size:512
- Epochs:100
from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(16, activation='relu', input_shape=(10000,))) model.add(layers.Dense(16, activation='relu')) model.add(layers.Dense(1, activation='sigmoid'))
將優化器設定為 rmsprop,損失函數使用 binary_crossentropy,將網路進行 Compile
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
訓練 CNN 模型
先將準備訓練的 25000 筆資料集,抽出 10000 筆資料集用在訓練時期的驗證資料,好讓我們監控訓練過程的準確性變化。如下:
x_val = x_train[:10000] partial_x_train = x_train[10000:] y_val = y_train[:10000] partial_y_train = y_train[10000:]
開始訓練模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=100,
batch_size=512,
validation_data=(x_val, y_val))
如果是是透過 Colab 的 GPU 進行訓練,每一個 Epoch 差不多 3 秒多一點,訓練結果如下:
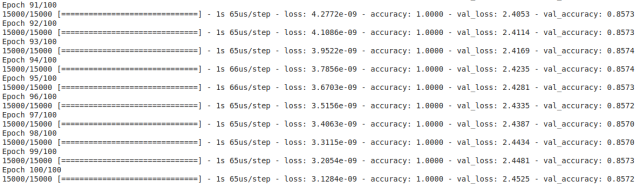
訓練的過程會把相關資訊存放在 history,透過事後分析訓練過程的資訊可以幫助我們優化參數。
history_dict = history.history history_dict.keys()
訓練結果圖表分析
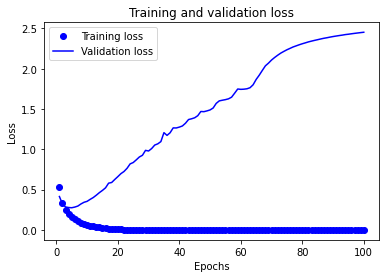
透過上面的方法可以取得訓練 History 包含的資訊,然後我們將資訊繪製成為圖表,首先觀察 loss 變化,如下:
#@title
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
執行結果:
接著透過以下程式產生圖表來觀察正確率的變化:
plt.clf() # clear figure
acc_values = history_dict['accuracy']
val_acc_values = history_dict['val_accuracy']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
執行結果:
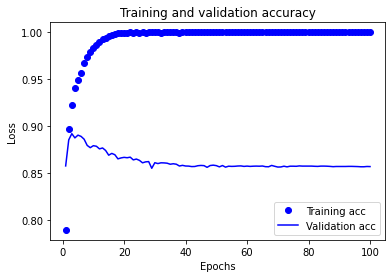
由上面的數據可以看出來,以現在的網路架構,其實在第 3 次 Epoch 就已經獲得最佳的結果,之後的訓練已經造成過度擬合 (Over Fitting),因此在這個案例中將 Epoch 設定為 3 或 4 是取得最佳訓練模型的方法。今天的範例程式可以在 GitHub 取得 ipynb 檔案,需要請自行下載。
原來算比較久不一定比較好 R~實務上,建議透過訓練過程的監控,可以選擇某一個 Epoch 獲得表現最好的 Model 作為最佳解。此外,模型的參數也是很重要的,下一篇文章我們就來介紹一下各種參數的使用情境,敬請期待.......