Apache Spark 最吸引人的地方就是內建了許多 Machine Learning Library (MLlib),一些基本的演算法與分類器可以不用自己寫囉。要進入 Machine Learning 算是降低了很多門檻,另外一個好處就是免費,不然 Matlab 也是貴鬆鬆。
安裝 Spark
今天要介紹的內容很簡單,就是只是把玩一下 Spark Machine Learning(或者被玩!)。首先我們先安裝 Spark,可以到官方網站下載最新的檔案,Package Type 可以選 Pre-built 的版本,這樣就不需要自行編譯了,安裝起來會省下不少時間。
今天測試的環境是 Ubuntu,Spark 下載後可以直接解壓縮,如下:
wget http://ftp.tc.edu.tw/pub/Apache/spark/spark-1.4.0/spark-1.4.0-bin-hadoop2.6.tgz
tar -zxvf spark-1.4.0-bin-hadoop2.6.tgz
接著把解壓縮後的檔案複製到 /usr/lib,如下:
mv spark-1.4.0-bin-hadoop2.6 /usr/lib
設定一下 PATH 環境變數,這樣才可以直接使用 Spark 指令,如下:
echo "export PATH=$PATH:/usr/lib/spark-1.4.0-bin-hadoop2.6/bin" >> /etc/bash.bashrc
安裝 Java Runtime Environment
由於 Spark 需要透過 Java 來執行,理所當然我們也應該安裝 JRE 環境,並且確認 JAVA_HOME 環境變數已經正確設定。Ubuntu 透過 apt 裝起來的 Java 是 OpenJDK,安裝 Java 我還是比較習慣安裝 Sun-JRE (現在是 Oracle),大部份的套件跑起來會比較沒有問題。Java 可以到這裡下載,下載後一樣解壓縮移動到 /usr/lib 即可。
tar -zxvf jre1.8.0_45.gz
mv jre1.8.0_45 /usr/lib
設定一下 PATH 與 JAVA_HOME 環境變數
echo "export JAVA_HOME=/usr/lib/jre1.8.0_45" >> /etc/bash.bashrc
echo "export PATH=$PATH:/usr/lib/jre1.8.0_45/bin" >> /etc/bash.bashrc
設定好之後記得重新登入好載入新的環境變數。可以執行 spark-shell 看看能不能正確啟動,如下:

Spark Machine Learning
Spark 已經內建了許多 Machine Learning 函式庫 (稱為 MLlib),像是一些分群演算法與分類器。接下來要測試的實驗為辨識「鳶尾花」,學界有一組鳶尾花 (學名 Iris) CSV 樣本資料,常用來作為演算法的訓練與辨識,其實我不知道「鳶尾花」是什麼鬼?只知道這組資料描述花的四組特徵,可以用來進行演算法的訓練與預測。開始之前,我們要先安裝 Python Num 函式庫,如下:
sudo apt install python-numpy
將運算搬到資料端,比起將資料搬過來算來得有效率,這也是雲端運算的基本概念。Spark MLlib 在計算時當然也可以透過 HDFS, HBase 來抓取資料,很容易實現分散式運算。很不幸我們今天只有一個運算單位,資料就直接放在檔案系統即可,先下載 iris.csv 檔案儲存到磁碟中。訓練與預測的程式在 GitHub 這裡可以下載,用 Python 寫的,本人第一次寫 Python,寫得很爛自己都看不懂,所以就不介紹程式碼囉,下載 iris.py 後透過以下命令來執行:
spark-submit iris.py
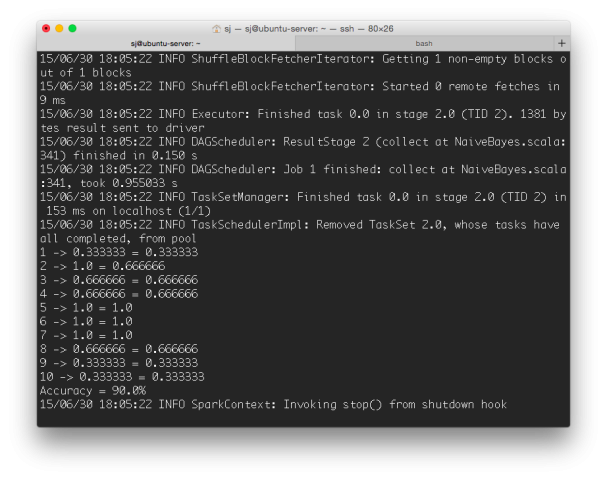
執行畫面如下,程式會隨機抽選十組資料進行預測,跑了幾次正確率都在 50% 以上,整個過程蠻容易的,先介紹到這裡,下次再見。