


在上一篇教學「訓練 IMDB Reviews CNN 網路模型」我們發現「原來算比較久不一定比較好 R~」,然而選擇適合的演算法是很重要的。其中 Keras 在神經網路訓練的時候需要帶入不同的訓練參數或驗算法,像是優化器與損失函數等等,這些參數應該如何選擇呢?我們這個章節就說明一下不同演算法適合應用的場景。
Keras Optimizer and Losses Function (優化器與損失函數)
由於 Keras 已經提供許多實做完整的優化器與損失函數,讓我們可以針對問題進行不同參數的搭配訓練,透過數次的實驗找出最適合解決問題的模型架構。以下是 Keras 常見的 Optimizer and Losses Function:
優化器 Optimizer
- SGD
- RMSprop
- Adagrad
- Adadelta
- Adam
- Adamax
- Nadam
損失函數 Losses
- mean_squared_error
- mean_absolute_error
- mean_absolute_percentage_error
- mean_squared_logarithmic_error
- squared_hinge
- hinge
- categorical_hinge
- logcosh
- categorical_crossentropy
- sparse_categorical_crossentropy
- binary_crossentropy
- kullback_leibler_divergence
- poisson
- cosine_proximity
從解決的問題型態選擇訓練參數
那應該如何選擇損失函數呢?一般來說,我們可以根據我們要解決的問題進行「損失函數」的選擇,所以選擇以前我們先分析我們想要用 AI 解決什樣的問題?
- 二元分類問題:二元交叉熵 (Binary Crossentropy),只有兩類的分類問題
- 多類別分類問題:分類交叉熵 (Categorical Crossentropy),超過兩類的分類問題,如文章分類
- 回歸問題:均方差 (Meansquared Error),擅長處理連續性的資料,如預測天氣溫度、房價
- 序列學習問題:連結時序分類 (Connectionist Temporal Classification, CTC)
確認問題的類型以後可以參考以下表格選擇參數:
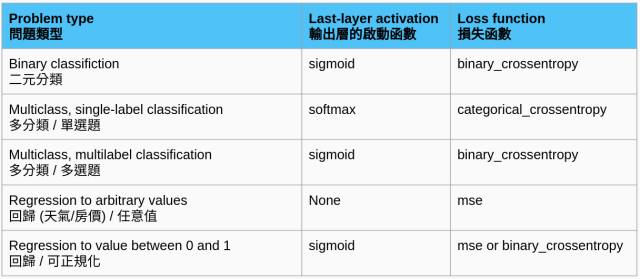

softmax:稱為歸一化函數,輸出值的「總和 = 1」
sigmoid:稱為 S 型函數,輸出值介於 0~1 的範圍
選擇神經元的數量,網路的神經元數量一定越多越好嗎?
神經元表示維度空間,越多的神經元表示假設空間越大,自由度越高,相對的計算成本會更加昂貴。
但維度太高有可能學習到不想要的 Pattern,造成 Over Fitting!訓練的時候可以嘗試不同的神經元數量來評估效果。
那麼要如何選擇參數與避免過度適配 (Over Fitting) 呢?設計網路的時候可以先參考以下五個技巧:
- 減少網路容量,避免神經元數量太多
- 更多訓練資料,避免訓練資料太少
- 神經元不得少於結果輸出的個數
- 使用權重常規化:避免較大的權重值主導整個模型
- 使用丟棄法:在 Layer 輸出加入雜訊,讓網路比較不會死記訓練資料
建立一個神經網路,訓練的過程一般來說會遇到「神經網路架構、啟動函數、損失函數、優化器、Epoch、Batch Size」這些變數,先把握大方向與原則,經過反覆實驗來找書最適合的網路設計。過程中常常需要耗費大量運算與時間,好在現在 GPU 越來越快了,就差在口袋的深度有沒有越來越深了.......
今天神經網路訓練參數就分享到這裡,接下來我們就開始進入現在最火紅的 CNN 囉~敬請期待.......